Uma das competências principais em um time de DevOps e Site Reliability Engineering é o monitoramento. A capacidade de medir efetivamente a saúde das aplicações e serviços e perceber rapidamente um problema e prevení-lo poupa muito dinheiro para as empresas. Portanto, devemos continuamente aprimorar nossas abordagens neste tema.
O Desafio atual
Antes do nascimento da nuvem, o problema do monitoramento era um pouco mais simples. Tipicamente tínhamos ambientes mais controlados, com 1 ou poucos datacenters por empresa e uma quantidade de aplicações e serviços relativamente controlada. Ferramentas como Nagios ou Zabbix já entregavam uma capacidade satisfatória para a maioria dos cenários. O inventário de servidores e ativos das empresas mudava com pouca frequência.
Hoje, entretanto, temos uma diversidade e dinâmica muito maior. Além dos componentes de infra base e de servidores em um modelo Infraestrutura-como-serviço (Iaas), é muito comum vermos aplicações rodando em containers ou componentes Serverless (PaaS) e também algumas aplicações Software-como-serviço (SaaS). Nestes cenários as métricas comuns de CPU, memória, disco e rede não farão sentido.
Como então monitorar bem nesse modelo heterogêneo?
Health-Checks de Aplicações
Complementar ao monitoramento de métricas de infra base, o Health Check de aplicações permite que tenhamos uma visão mais clara do funcionamento de todos os componentes de forma integrada. A idéia é bem simples: a aplicação expõe uma URL HTTP de health check, que deve retornar um Status 200 se tudo estiver bem e um Status 5xx caso o serviço esteja com problemas.
Porém, um ponto importante deve ser considerado: caso o serviço esteja degradado, mas não completamente indisponível, é mais indicado retornar um status 200 e alarmar a degradação em algum outro canal. Caso o serviço retorne um status 5xx, o balanceador ou orquestrador de containers entenderá o nó em questão como indisponível e cortará integralmente a comunicação com o mesmo. Isto trará um dano maior do que a degradação parcial da aplicação.
Matriz de Resiliência o que é?
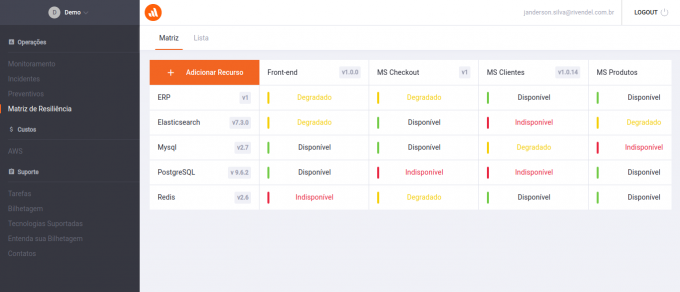
A Matriz de Resiliência é um serviço que permite criar um inventário de todos os recursos do seu ambiente, sejam eles aplicações, serviços de infraestrutura próprios ou de terceiros e qualquer outro tipo de recurso que necessitar.
Um mapeamento que consideramos muito importante é o das dependências das aplicações, que podem ser serviços de infraestrutura ou outras aplicações. Este modelo passou a ser conhecido por nós após um material compartilhado pelo time de Engenharia do Shopify. Depois de algum tempo passamos a adotar no monitoramento e documentação das aplicações e ambientes que suportamos.

Neste exemplo, temos 4 aplicações, cada uma com sua respectiva coluna. As linhas representam os serviços de infraestrutura e algumas aplicações que são dependências para outras. Marcamos as células com uma das 3 opções:
- Disponível: quando a aplicação daquela coluna não sofre impactos caso o serviço da linha em questão estiver indisponível
- Degradado: quando a aplicação daquela coluna sofre uma degração quando o serviço da linha em questão estiver indisponível, mas a aplicação ainda preserva parte de sua funcionalidade
- Indisponível: quando a aplicação em questão não tolera falhas no serviço e fica indisponível caso este também esteja
Fazendo este mapeamento, passamos a ter uma visão clara de quais são as dependências de cada aplicação e para cada célula marcada como “Indisponível”, passamos a ter condições de refletir sobre como fazer a aplicação em questão degradar em vez de ficar totalmente indisponível.
Discussões sobre tolerância a falhas são muito importantes para tornar aplicações mais robustas e disponíveis, pois mesmo os componentes mais resilientes terão incidentes algumas vezes por ano.
Template da Matriz de Resiliência:
Você pode usar agora e ter acesso imediato aos benefícios da Matriz de Resiliência. Acesse o módulo Cloud Compliance (MCP), para clientes Mandic basta utilizar seu e-mail ou código de cliente para se autenticar, se não for cliente saiba mais sobre Cloud Compliance do MCP.
Melhorando nossos Health-Checks
Tendo a visão das dependências de cada aplicação, temos condições de propor um refinamento aos nossos Health-Checks: validar o bom funcionamento de cada uma de suas dependências. Neste caso, não queremos saber somente se a dependência em si está saudável. Queremos garantir que nossa aplicação está conseguindo utilizá-la para suas necessidades.
Neste contexto, a implementação do Health-Check da aplicação deveria tentar validar com alguma operação simples que o uso de cada dependência está ocorrendo conforme esperado. Fazendo isto, sugerimos o retorno de um payload JSON simples, semelhante ao seguinte:
{
“mysql” : “OK”,
“redis” : “NOK”,
“appXPTO” : “OK”
}
Temos múltiplos atributos com chave e valor, representando cada dependência e o valor OK ou NOK para descrever se a aplicação está conseguindo usá-la com sucesso ou não. Com isso, uma simples requisição GET feita pelo monitoramento já trará uma ótima visão sobre a saúde da aplicação e sobre a provável origem caso tenhamos um incidente.
Recomendamos que isto seja implementado para todas as aplicações e que tenhamos uma ou mais matrizes de resiliência documentando a relação entre cada aplicação e suas dependências. Esta abordagem é simples de implementar e nos traz sensíveis ganhos no tempo de diagnóstico e resolução de problemas.
Tem alguma recomendação para melhorar ou complementar este modelo? Ficaremos felizes de saber! Deixe nos comentários 🙂
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.
